Classification of Iris dataset
Hi everyone !
I’m Sriraag and this my first ever blog on Machine learning. In this blog i’ll try to perform machine learning classification processes on Iris data set. I’ll be using CART , logistic regression , Perceptron , Neural network and random forest. Let’s get some basic idea on what is iris.
WHAT IS IRIS ?
Iris is the family in the flower which contains the several species such as the iris.setosa,iris.versicolor,iris.virginica,etc.

LETS UNDERSTAND THE DATASET…..
The data set consists of:
- 150 samples
- 3 labels: species of Iris (Iris setosa, Iris virginica and Iris versicolor)
- 4 features: Sepal length,Sepal width,Petal length,Petal Width in cm
So now let us write the python code to load the Iris dataset.
from sklearn import datasets
iris=datasets.load_iris()Assign the data and target to separate variables.
x=iris.data
y=iris.targetSplitting the dataset;
Since our process involve training and testing ,We should split our dataset.It can be executed by the following code
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=.5)x_train contains the training features
x_test contains the testing features
y_train contains the training label
y_test contains the testing labels
Build the model
We can use any classification algorithm to solve the problem.we have solved the previous problem with decision tree algorithm,I will go with that.
from sklearn import tree
classifier=tree.DecisionTreeClassifier()The above code will create the empty model. Inorder to provide the operations to the model we should train them.
Note:We can also use KNeighborsClassifier(efficiency is higher)
from sklearn import neighbors
classifier=neighbors.KNeighborsClassifier()At this point,We have just made the model.But it cannot able to predict whether the given flower belongs to which species of Iris .If our model has to predict the flower,We have to train the model with the Features and the Labels.
Train the Model.
We can train the model with fit function.
classifier.fit(x_train,y_train)Now the model is ready to make predictions
Make predictions:
Predictions can be done with predict function
predictions=classifier.predict(x_test)these predictions can be matched with the expected output to measure the accuracy value.
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,predictions))
The first accuracy score is done through process of decision tree.
Logistic Regression
Importing libraries required for Logistic regression
from sklearn.linear_model import LogisticRegression
from sklearn import metricsClassifying dataset using logistic regression. Logistic regression uses Sigmoid function for predicting values.
logreg = LogisticRegression()
logreg.fit(X_train, y_train)Predicting y values and comparing it with real y values for accuracy and viability of the model.
y_pred = logreg.predict(X_test)
print('Accuracy of logistic regression classifier on test set: {:.2f}'.format(logreg.score(X_test, y_test)))

Classification Report
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))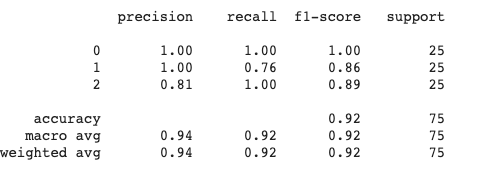
Perceptron
Perceptron is simplest form of neural network. Classifying wine dataset using Perceptron. Importing necessary libraries for single layered neural network and predicting .
pn = Perceptron(tol=1e-3, random_state=0)
pn.fit(X_train, y_train)Training Accuracy
pn.score(X_train,y_train)
Testing Accuracy
pn.score(X_test,y_test)
Neural Network
Neural networks are a set of algorithms, modeled loosely after the human brain, that are designed to recognize patterns. They interpret sensory data through a kind of machine perception, labeling or clustering raw input. The patterns they recognize are numerical, contained in vectors, into which all real-world data, be it images, sound, text or time series, must be translated. Neural networks help us cluster and classify.
Importing libraries for neural network
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categoricalSpecifying model type, input shape and configuring compile method
x_train = np.array(x_train)
model = Sequential()
model.add(Dense(4, input_dim=4 ,activation='relu'))
model.add(Dense(7, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])Training and Testing of Dataset
y_test_cat=to_categorical(y_test)
y_train_cat=to_categorical(y_train)
model.fit(x_train, y_train_cat, epochs=149, batch_size=4)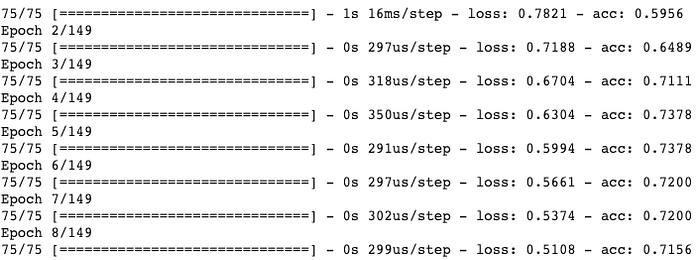

Training Accuracy
_, accuracy = model.evaluate(X_train, y_train_cat)
print('Accuracy: %.2f' % (accuracy*100))
Testing Accuracy
_, accuracy = model.evaluate(X_test, y_test_cat)
print('Accuracy: %.2f' % (accuracy*100))
Random Forest
Random forest, like its name implies, consists of a large number of individual decision trees that operate as an ensemble. Each individual tree in the random forest spits out a class prediction and the class with the most votes becomes our model’s prediction.
Random Forest Classification
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 900, criterion = 'gini', random_state = 0)classifier.fit(X_train, y_train)y_pred = classifier.predict(X_test)Accuracy
print(classifier.score(X_test, y_test)

SUMMARY
For Iris Dataset it is evident that Neural networkis the best classification method. Following Random Forest,CART and Logistic Regression were also precise with accuracy 0.973.
